

If you are running a large website with many pages then it is essential that you know exactly what a crawl budget is, how it’s affecting your site, what your budget is and what to do if it’s not enough.
What exactly is a crawl budget?
The crawl budget is how many times the Google bots or spiders are crawling pages on your website within a given period of time. If you only have a small or medium sized site then this is most likely not going to be a problem, if you have a large site with hundreds, thousands or even tens of thousands of pages (such as an e-commerce site or news/media site) then you need to know that Google is crawling as many of these pages as possible and if changes are being made to these pages that they are re-crawled soon after.
The main factor that affects the crawl budget is PageRank, so for large and established sites its often not a problem, however if you site is relatively new and you are adding many new pages to it then the lank of PageRank could be a problem.
Matt Cutts summarized crawl budget perfectly in this interview published at Stone Temple some years back:
“The first thing is that there isn’t really such thing as an indexation cap. A lot of people were thinking that a domain would only get a certain number of pages indexed, and that’s not really the way that it works. There is also not a hard limit on our crawl. The best way to think about it is that the number of pages that we crawl is roughly proportional to your PageRank. So if you have a lot of incoming links on your root page, we’ll definitely crawl that. Then your root page may link to other pages, and those will get PageRank and we’ll crawl those as well. As you get deeper and deeper in your site, however, PageRank tends to decline.“
That interview was way back in 2010 and there have been many changes to how Google crawls sites such as the Caffeine update in June of that year and Google is able to crawl more pages and a lot faster now but what Matt said back then about Google focusing on pages with more authority still remains true, these pages are just going to be crawled with greater frequency now.
How does Google crawl your pages?
First the Google spider will look into your robots.txt file and see what it should and shouldn’t be crawling and indexing. The budget part is how many of these urls Google decides to crawl per day, this is decided by the health of your site and also the number of links pointing to it.
How to check the health of your crawl budget
First check the total number of pages your site has in its XML sitemap, usually this will be at the root of your site eg Yourdomain.com/sitemap.xml. Quick tip, if you don’t have a sitemap setup and are running a WordPress site then we strongly recommend the YOAST SEO plugin which will do all of this for you with just a few clicks 🙂
Within your sitemap XML file there will be other sitemaps for different parts of your site eg a sitemap for the blog posts, one for different authors or users and so on. Go into each of these and get the total number of pages for each.
Once you have your total number of pages go into your Google Webmaster Tools account and then to Crawl>Crawl Stats in the left side menu until you see the pages crawled per day like the image below.
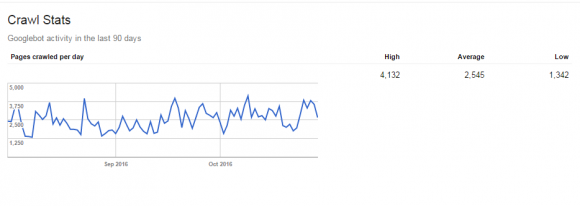
Then to find out your crawl budget simply divide the total number of pages your site has by the average number of pages crawled per day.
If your final number is less than 10 you are fine, if its more then you have a problem as Google has not allocated a you a large enough crawl budget and thus not all of your pages are being crawled, this needs to be fixed.
My crawl budget is bad, now what?
First off you need to find out if there are any crawl errors being found by Google on your site. Your server logs are a good place to start, you want to be looking for any 404s and redirecting them if possible or fixing the pages. 301 and 302’s are ok as long as they are redirecting to the correct places.
Once you have cleaned up crawl errors your next step should be to look at how Google is crawling your site.
How to sculpt where Google bots go
Remember, there are a finite number of pages on your site that Google can crawl, however Google bots will parse anything put in front of them so we need to make sure that they aren’t crawling pages that aren’t important to your site.
Robots.txt file – use this a the top level for disallowing sections of your site from bots being able to crawl
Noindex meta tag – this can be used on a more finite level for individual pages so that they will not be indexed
Nofollow tags – this can be used at an even more granular level on individual links to pages but if you don’t add this tag to all links pointing to the page then Google will still be able to find it
Knowing how and when Google bots are crawling your site is crucial for mid-range to large sites, especially ones that might not have so much authority and are competing against more established sites so webmasters have to ensure that these bots are seeing and crawling the most important parts of their site.
For more in-depth and further information on how Google is crawling websites see this Google hangout with John Mueller and Andrey Lipattsev.
Stop Letting Visitors Slip Through Your Fingers By Implementing These Conversion Tips
Superb detailing about Crawl Budget
Great blog, Thanks for posting.